If your team already has coding guidelines and standards documented, point CodeRabbit to them using Code Guidelines.
Path instructions
Add custom review instructions for specific file paths using glob patterns. Instructions let you tell CodeRabbit exactly what to focus on for any part of the codebase.Configure path instructions
- Configuration file
- Web UI
.coderabbit.yaml
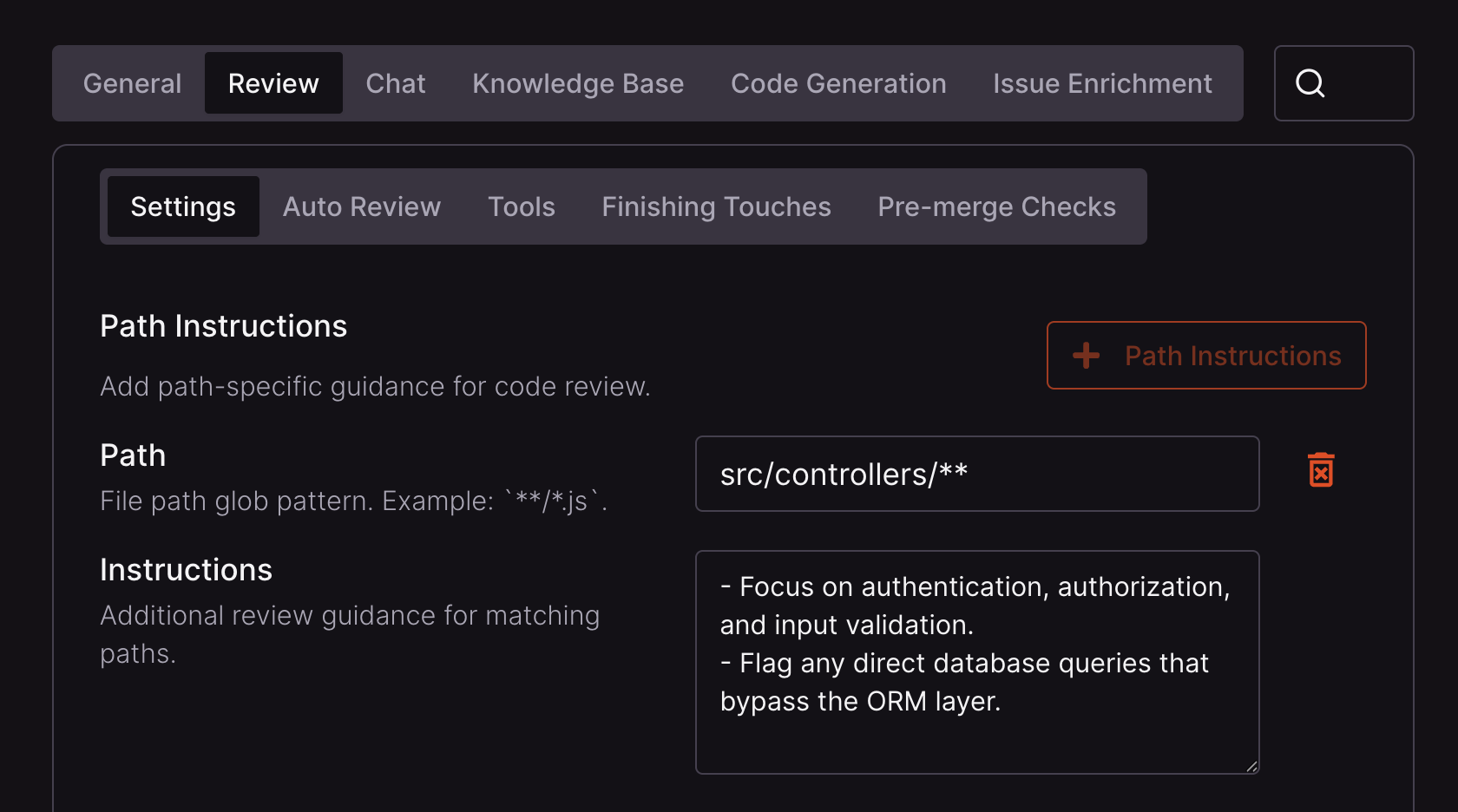
Paths accept glob patterns. See the minimatch documentation for more information.
When to add path instructions
CodeRabbit’s built-in review logic covers a wide range of issues by default. Path instructions work best as a targeted supplement, not a replacement.- Observe a few reviews first. If something is consistently missed or needs to be applied differently for a specific part of the codebase, that’s a good candidate for a path instruction.
-
When you identify a gap, consider which mechanism fits best:
- Path instructions — rules scoped to specific files or directories in CodeRabbit’s review.
- Code guidelines — existing standards documents (like
AGENTS.mdor.cursorrules) that CodeRabbit picks up automatically, and that also benefit AI coding agents. - Custom checks — pass/fail conditions you define that run as part of every review.
After CodeRabbit has reviewed several pull requests, it may have accumulated path-instruction suggestions. Post
@coderabbitai emit path instructions as a PR comment to collect suggestions from the past 7 days and open a pull request that merges them into your .coderabbit.yaml without overwriting existing entries. See the command reference for details.Path filters
Path filters control which files CodeRabbit includes or excludes from review. Excluding irrelevant files, such as lock files, binaries, and generated code, keeps reviews focused and fast. CodeRabbit ships with sensible defaults, but you can extend the ignore list with your own patterns, or override defaults to force-include paths that would otherwise be skipped.Configure path filters
Patterns prefixed with! exclude paths from review (for example, !dist/** skips the dist folder). Patterns without ! include paths explicitly, which is useful for overriding a default exclusion.
Path filters define CodeRabbit’s review scope. Files excluded here, or skipped by the default ignored paths below, do not appear in CodeRabbit review surfaces such as the walkthrough or Change Stack. GitHub can still show those files in the pull request’s full file list.
- Configuration file
- Web UI
.coderabbit.yaml
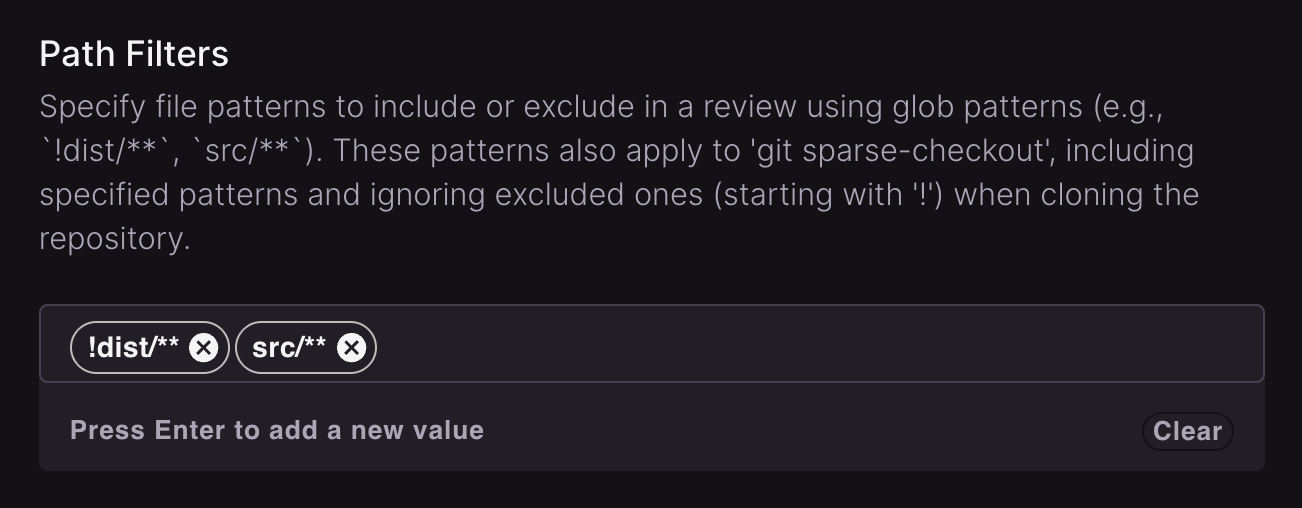
Default ignored paths
By default, CodeRabbit intentionally skips certain file paths and extensions — things like lock files, binaries, generated code, and media assets. If you want CodeRabbit to review any of these, you can explicitly include them in your Path Filters configuration.Default ignored paths
Default ignored paths
Build and dependency directories
Build and dependency directories
Lock files
Lock files
Generated code
Generated code
Binary and compiled files
Binary and compiled files
Archives and compressed files
Archives and compressed files
Media files
Media files
Images and fonts
Images and fonts
Documents and data files
Documents and data files
Development and system files
Development and system files
Game and 3D assets
Game and 3D assets
Python-specific files
Python-specific files
Go-specific files
Go-specific files
Terraform files
Terraform files
Xcode-specific files
Xcode-specific files
Minified files
Minified files
What’s next
AST-based instructions
Write review instructions using ast-grep rules for precise, syntax-aware review instructions.
Code guidelines
Point CodeRabbit to your existing coding standards documents:
AGENTS.md, .cursorrules, and similar files.Custom checks
Define pass/fail conditions that run as part of every review to enforce your team’s standards automatically.